Transcribing Interviews
Transcribe audio and video files into text for analysis.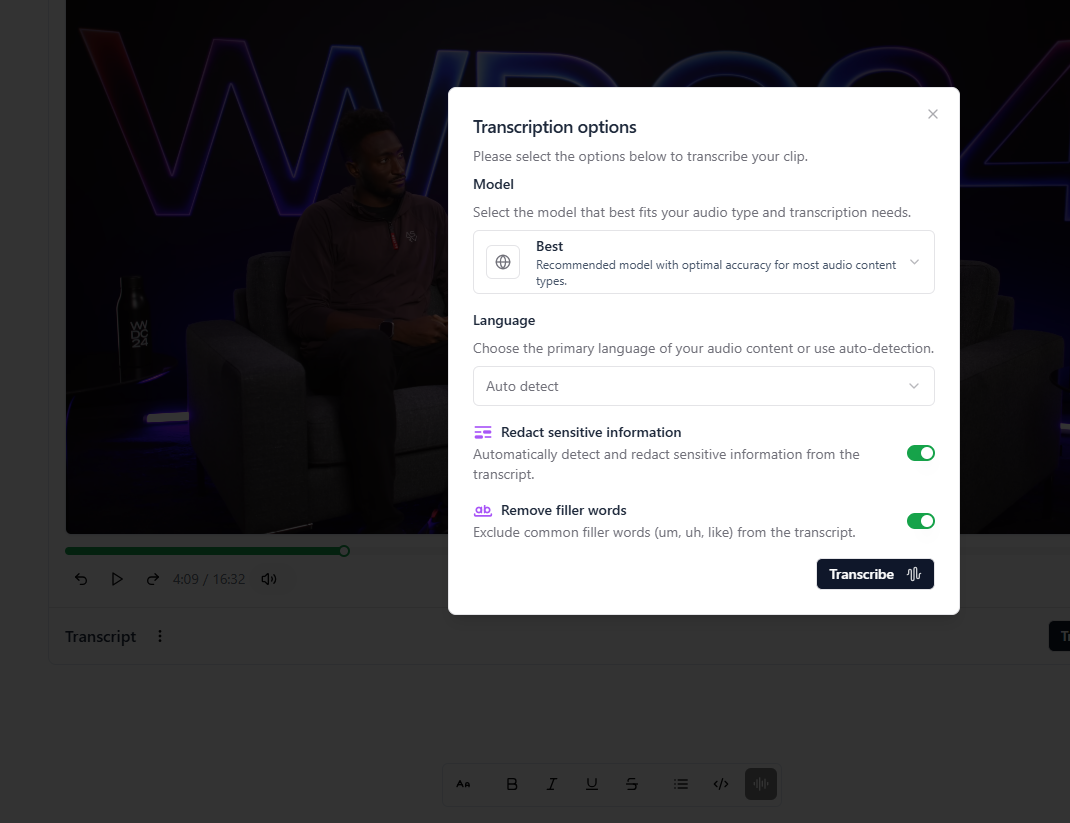
Settings
Configure default transcription settings in Workspace Settings > Transcription Settings:- Auto-transcribe on upload: Start transcription automatically
- Model selection: Choose the transcription model
- Language selection: Set default language or auto-detect
- Redaction: Enable automatic redaction of sensitive information
- Filler words: Include or exclude filler words
- Custom vocabulary: Add unique words, names, or jargon (one word per line)
Process
- Create a new document
- Click Upload audio or video in the document editor
- Select your file
- Click Transcribe and configure settings:
- Redaction: Redact sensitive information (names, addresses)
- Exclude filler words: Remove “uh,” “um,” etc.
- Language: Select language or use Autoselect
Supported formats
- Video: .mp4, .webm, .ogv, .avi, .mov, .mkv
- Audio: .mp3, .wav, .ogg, .aac, .webm, .flac
Models
General Purpose
- Nova-2: Latest model, supports all available languages
- Enhanced General Purpose: Improved accuracy, subset of languages
- Base General Purpose: Moderate language support
Specialized (English only)
- Meeting: Multi-speaker meetings
- Phone Call: Two-speaker conversations
- Financial: Financial terminology
- Medical: Healthcare terminology
- Automotive: In-car audio